
2080 TIリリース日
しかし、そのニュースのより大きな側面は、Nvidia独自のキャッシュコヒーレントGPUインターコネクトnvlinkが消費者カードに来ることです. GEFORCE GTXカードは、各カード間で2つのNVLINKチャンネルを実行してSLIをNVLINK上に実装します. 全二重帯域幅の合計50GB/秒 – つまり、各方向に50GBの帯域幅があります – これは、NVIDIAの以前のHB-SLIリンクに対する主要なアップグレードです. これは、NVLinkの他の機能の利点、特にキャッシュコヒーレンスの上にあります. そして、これはすべて重要な時期に来ます。.
Nvidia GeForce RTX 2080 TIグラフィックスカード
改造されたGeForce RTX 2080 TIは22GBのGDDR6メモリをサポートしています
TeclabはGeforce RTX 2080 Tiで3GHz GPUクロックバリアを破壊します
NvidiaはGeforce RTX 2080(TI/Super)およびGeForce RTX 2070(Super)グラフィックスカードを引退すると噂されています
MSIアウトGEFORCE RTX 2080 TI GAMING Z 16 GBPS GDDR6メモリ
NvidiaはGeForce RTX 2080 Ti「Cyberpunk 2077 Edition」を発表しました
AsusはGeforce RTX 2080 Ti Rog Strix White Editionを披露します
Gigabyteは、RTX 2080 Tiを使用してAorus Gaming Boxを起動します
Galax GeForce RTX 2080 Ti HOF 10周年記念版が発見されました
MSI RTX 2080 Ti Lightning 10th Anniversary Edition写真
MSIはGeForce RTX 2080 Ti Lightning 10th Anniversary Editionをからかいます
(PR)MSIはGeForce RTX 2080 Ti Lightning Zを発表します
EVGA GeForce RTX 2080 Ti Kingpin Editionはハイブリッドです
MSI GeForce RTX 2080 Ti Lightning写真
AsusはROG GeForce RTX 2080 Ti Matrixを紹介します
カラフルなgeforce rtx 2080 ti igame kudan smiles for camera
MSIはカーボンファイバーGeForce RTX 2080 Ti Lightning Zをからかいます
ZOTAC GEFORCE RTX 2080 TI ARCTICSTORM TO CES 2019でデビューする
MSI GeForce RTX 2080 Ti Lightning Z PCB写真
カラフルな発売geforce rtx 2080(ti)rng edition with full color lcd
(PR)INNO3DがGeForce RTX Ichill Frostbiteシリーズを発表
EvgaはGeForce RTX 2080 Ti Kingpinをからかいます
Geforce RTX 2080 Ti Aorus Turboの準備のギガバイト
Nvidiaは、Battlefield Vを無料でGeForce RTXでバンドルします
(PR)ManliはGeforce RTX 2080 Ti&2070をブロワーファンで発表します
新しいカードレポート#21:RTX RGBエディション
Inno3dはGeForce RTXカードを巨大なRGBクリスマスツリーに変える
MSIはGEFORCE RTX 2080(TI)SEA HAWK(EK)Xシリーズを発表します
Gigabyte Teases GeForce RTX 2080(TI)Aorus Graphics Card
nvidia geforce rtx 2080 ti&rtx 2080レビューラウンドアップ
TechPowerupは、チューリングAと非A GPUバリアントの違いを説明しています
nvidia geforce rtx 2080 tiおよびrtx 2080「公式」パフォーマンスが発表された
Nvidiaチューリングアーキテクチャの新機能
nvidiaがGEFORCE RTX 2080レビュー日付を9月19日に変更する
Nvidia Geforce RTX 2080レビューは9月17日に公開されます
EVGAは、水力銅およびハイブリッドGeForce RTXモデルを発表します
- 2025 GEFORCE 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GEFORCE 40
- 2021 GEFORCE 30モバイル
- 2020 GEFORCE 30
- 2019 GEFORCE 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GEFORCE 20モバイル
- 2016 GEFORCE 10
- 2016 GEFORCE 10モバイル
- 2014 GEFORCE 800モバイル
- 2014 GEFORCE 900
- 2014 GEFORCE 900モバイル
- 2013 GEFORCE 700
- 2013 GEFORCE 700モバイル
- 2012 GeForce 600
- データセンター /テスラ
- テグラ
- ワークステーション /クアドロ
- GeForce MX
- Titan RTX
- GeForce RTX 2080 Ti
- GeForce RTX 2080スーパー
- GeForce RTX 2080
- GeForce RTX 2070スーパー
- GeForce RTX 2070
- GeForce RTX 2060スーパー
- GeForce RTX 2060 12GB
- GeForce RTX 2060
- GeForce MX250
- 3Dスタッキング
- アクセサリー
- 発表
- りんご
- 腕
- 人工知能
- 自動車産業
- ベンチマーク
- ビジネスと市場
- 中国のグラフィックス
- 概念
- 接続性
- コンテンツ作成
- 冷却技術
- 暗号通貨
- カスタムプロジェクト
- 取引
- ディスプレイとモニター
- イベント
- 外部GPUおよびエンクロージャー
- 外部レビュー
- 極端なオーバークロック
- 財務結果
- ファウンドリー
- ゲームバンドルと取引
- ゲーム要件
- ゲームストリーミング
- ゲーム
- ゲームコンソール
- ゲームハードウェア
- グラフィックス
- グラフィックアピス
- インタビュー
- Linux
- メモリテクノロジー
- MINI/SFF/NUC PC
- モバイルデバイス
- 改造
- マザーボード
- ノートブック
- 特許と研究
- PCケース
- PCI Express
- 人々
- 電源
- 事前に構築されたシステム
- RISC-V
- 安全
- ソフトウェアとドライバー
- ストレージ
- スーパー解像度
- スーパーコンピューティング(HPC)
- ビデオコーディング
- バイラルストーリー
- バーチャルリアリティ
- 水冷
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000 Mobile
- 2022 Radeon 7000
- 2021 Radeon 6000 Mobile
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000 Mobile
- 2017 Radeon 500
- 2017 Radeon 500モバイル
- 2016 Radeon 400
- 2016 Radeon 400 Mobile
- 2015 Radeon 300
- 2015 Radeon 300 Mobile
- 2014 Radeon 200モバイル
- 2013 Radeon 200
- レイドンの本能
- Radeon Pro
- ブロックチェーン計算
- 2025 GEFORCE 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GEFORCE 40
- 2021 GEFORCE 30モバイル
- 2020 GEFORCE 30
- 2019 GEFORCE 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GEFORCE 20モバイル
- 2016 GEFORCE 10
- 2016 GEFORCE 10モバイル
- 2014 GEFORCE 800モバイル
- 2014 GEFORCE 900
- 2014 GEFORCE 900モバイル
- 2013 GEFORCE 700
- 2013 GEFORCE 700モバイル
- 2012 GeForce 600
- データセンター /テスラ
- テグラ
- ワークステーション /クアドロ
- GeForce MX
- 2025 ARC DRUID TBA
- 2024 ARC CELESTIAL TBA
- 2023 ARC Battlemage TBA
- 2022 ARC錬金術師
- 2022 Intel Data Center HPC TBA
- 2021 Intel Data Center HP TBA
- 2020 Intel XE-LP
- Arc Pro
2080 TIリリース日
公式NVIDIA RTX 2080 TI、2080、および2070仕様、価格、リリース日
2018年8月20日午後3時に発行されたスティーブバークによる

アップデート: 完全な詳細がリークされたので、SM / CUDAコア番号の修正を追加しました.
Nvidiaは、RTX 2080 TI、RTX 2080、RTX 2070を含む、今日のゲーム用の新しいチューリングビデオカードを発表しました。. カードは、アップグレードされたが、なじみのあるVoltaアーキテクチャで前進し、SMSとメモリにいくつかの変更があります. 新しいRTX 2080および2080 TIシップは、最初に参照カードを搭載し、パートナーカード 主に同時に(1か月以上後に来るより高度なモデルがいくつかあります), どのパートナーに依存します. 取締役会のパートナーは、メディアとほぼ同じ時期まで価格設定やカードの命名を受け取らなかったので、カスタムソリューションの遅延を期待してください. 私たちはもともとパートナーカードで1〜3か月の遅延を聞いていましたが、それは現在生産に入っている先進モデルのみであるように見えます. ほとんどのトライファンモデルは同じ日付に利用可能になるはずです.
もう1つの重要なポイントは、デュアル軸リファレンスカードを使用するというNvidiaの決定であり、ローエンドでパートナーカードの価値の多くを排除することです。. ブロワーリファレンスカードからデュアルファンカードへの移動は、すぐにボードパートナーに影響を与えることができます。これは、消費者向けの販売を拡大し、パートナーをバイパスするNVIDIAのゆっくりとしたクロールにつながる可能性があります。. RTX 2080 TIの価格は1200ドルで、9月20日に発売され、2080は800ドル(および9月20日)、2070ドル(TBDリリース日)で発売されます。.
NVIDIA RTX 2080 TIおよび2080仕様
新しいGPUを比較するときに人々が犯す最大の間違いの1つは、「コアカウントについて話すことです.」これはいくつかの理由で誤りがあります。その1つは、コア向けのパフォーマンスが同一ではないということです。. ケプラーからパスカルまで、ワットあたりのパフォーマンスの効率全体で30%以上の利益があり、コアカウント間で線形比較を描くだけではこれに対応できません. また、CUDAコアはそうではありません 本当に とにかくコア:それらは浮動小数点ユニットです. SMは、標準の定義によってコアにより類似しており、コアが命令を取得および解読し、それらを実行し、レジスタとキャッシュとの間でデータの読み取りと書き込み、および結果を計算できるようにすることを求めています。. Nvidiaのフローティングポイントユニットは結果を計算できますが、他の多くのことはできません.
これをすべて言っているのは、厳格なパスカル対ということです. チューリングコアの比較は、「コア」が最初にどの程度機能するかを変える可能性のある建築の違いを説明する必要があります. 前回、人々は同じtrapに陥りました.
NVIDIA RTX 2080 TI、2080、および2070 Founders Edition Specs
NVIDIAの新しいRTX 2080 TIホスト4352フローティングポイントユニット、RTX 2080非TIホスティング2944 FPU. Nvidiaは、ストリーミングマルチプロセッサごとに64 FPUに固執しており、2080 TIを68 SMSに、2080は46 SMSに配置していました。. NvidiaはこのGPUのSMアーキテクチャを作り直したので、まだすべての詳細については肯定的ではありません.
新しいGPUは、予想されるシフトであるGDDR6にも移動します. 現在、GDDR6はGDDR5よりも約20%高いBOMコストを実行していますが、そのコストは時間とともに低下します. GDDR6は、RTX 2080および2080 TIでピンあたりの最小14Gbpsをピンスループットに最小限に抑えることができます。. GDDR6はピンあたり最大16Gbpsを押すこともできますが、新しいGPUについてはそれについての即時の約束はありません. GDDR6のメモリのタイミングの影響についてまだわかりません. 2080 Tiは、352ビットメモリバスで11GBのGDDR6をホストし、620GB/sの近くにメモリ帯域幅があります. RTX 2080は256ビットインターフェイスで8GBのGDDR6をホストし、したがって448GB/sメモリ帯域幅を許可します.
| RTX 2080 TI | RTX 2080 | RTX 2070 | |
| fp32 fpus( “cuda cores”) | 4352 | 2944 | 2304 |
| ストリーミングマルチプロセッサ | 68 | 46 | 36 |
| コアクロック /ブーストクロック | 1350/1545 FE:1635MHz | 1515/1710 FE:1800MHz | 1410/1620 FE:1710MHz |
| メモリインターフェイス | 352ビット | 256ビット | 256ビット |
| 記憶容量 | 11GB | 8GB | 8GB |
| GDDR6速度 | 14gbps | 14gbps | 14gbps |
| メモリ帯域幅 | 616GB/s | 448GB/s | 448GB/s |
| SLI | nvlink 2ウェイ | nvlink 2ウェイ | TBD |
| TDP | 〜265〜285W | 〜250-260W | 175-185W |
| 価格 | 1,200ドル または$ 1000* | 800ドル または700ドル* | 600ドル または500ドル* |
| 発売日 | 9月. 20、2018 | 9月. 20、2018 | TBD |
*価格のソース:Nvidiaのウェブサイト. 注記: また、価格が(おそらく無Feカード用の場合も聞いたことがあります? または、Nvidia内に誤解があります?)1070で500ドル、2080年で700ドル、2080 TIで1000ドルにすることもできます. これはfevsかもしれないと思います. 参照しますが、それはまた、Nvidiaのチームによる誤解である可能性があります. 現時点では明確ではありません.
NvidiaはGeForce RTX 20シリーズを発表します:RTX 2080 Ti&2080 on 9月. 20日、10月のRTX 2070

Nvidia’s Gamescom 2018の基調講演はまとめたばかりで、先月発表されて以来多くの人が期待してきたように、Nvidiaは次世代のGeforceハードウェアを立ち上げる準備をしています. イベントで発表され、9月20日から発売されるのはNvidiaのGeforce RTX 20シリーズで、現在のPascal搭載のGeforce GTX 10シリーズに続いています. NVIDIAの新しいチューリングGPUアーキテクチャに基づいて、TSMCの12NMの「FFN」プロセスに基づいて構築されているNVIDIAは、ゲームのレンダリング方法とPCビデオカードの評価方法のパラダイム全体の変化を促進しようとしています。. CEOのジェンセン・ファンは、2006年のテスラGPUアーキテクチャ(G80 GPU)以来、チューリングNvidiaの最も重要なGPUアーキテクチャを呼び出しており、機能の観点からは、彼が問題を誇張していないことは明らかです.
伝統的にそうであるように、Nvidia stableの最初のカードはハイエンドカードです. しかし、伝統からのかなり大きな休憩で、私たちは発売時にX80およびX70カードを取得するだけでなく、X80 TIカードも取得するつもりです. GEFORCE RTX 2080 TI、RTX 2080、およびRTX 2070を意味します。. Nvidiaの製品スタックはここでは変更されていないため、RTX 2080 Tiはフラッグシップカードのままであり、RTX 2080はハイエンドカードであり、RTX 2070は銀行を壊すことなく、わずかに安価な愛好家を誘惑するわずかに安いカードです。.
3枚のカードはすべて、今後2か月で発売されます. まず、9月20日に発売されるRTX 2080 TiおよびRTX 2080が . RTX 2080 TIはパートナーカードの999ドルから始まり、RTX 2080は699ドルから始まります. 一方、RTX 2070は10月のある時点で発売され、パートナーカードは499ドルから始まります. 歴史的には、これらの価格はすべて、最後の世代よりも120ドルから300ドルの間に高くなっています. 一方、Nvidia自身の参照品質の創設者版カードが再び戻ってきました。.
残念ながら、Nvidiaはすでに先行予約を取っているので、消費者は本質的に最初のバッチからカードを引っ掛けたい場合は「ブラインド購入」を行う必要があります. Nvidiaはパフォーマンスに関する驚くほどほとんど情報を提供していないので、信頼できるサードパーティのレビューを待つことをお勧めします(i.e. 私たち)、しかし、私は路上でのレビューが訪れるまでに多くの在庫があるとは思わないことを認めなければなりません.
| nvidia geforce仕様の比較 | ||||||
| RTX 2080 TI | RTX 2080 | RTX 2070 | GTX 1080 | |||
| CUDAコア | 4352 | 2944 | 2304 | 2560 | ||
| コアクロック | 1350MHz | 1515MHz | 1410MHz | 1607MHz | ||
| ブーストクロック | 1545MHz | 1710MHz | 1620MHz | 1733MHz | ||
| メモリクロック | 14GBPS GDDR6 | 14GBPS GDDR6 | 14GBPS GDDR6 | 10gbps gddr5x | ||
| メモリバス幅 | 352ビット | 256ビット | 256ビット | 256ビット | ||
| vram | 11GB | 8GB | 8GB | 8GB | ||
| 単一の精度パフォーマンス. | 13.4 Tflops | 10.1 tflops | 7.5 Tflops | 8.9 Tflops | ||
| テンソルパフォーマンス. | 440T OPS (INT4) | ? | ? | n/a | ||
| レイパフォーマンス. | 10グレイ/s | 8グレイ/s | 6グレイ/s | n/a | ||
| 「rtx-ops」 | 78t | 60T | 45t | n/a | ||
| TDP | 250W | 215W | 175W | 180W | ||
| GPU | 大きなチューリング | 名前のないチューリング | 名前のないチューリング | GP104 | ||
| トランジスタカウント | 18.6b | ? | ? | 7.2b | ||
| 建築 | チューリング | チューリング | チューリング | パスカル | ||
| 製造プロセス | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 16nm | ||
| 起動日 | 2018年9月20日 | 2018年9月20日 | 10/2018 | 2016年5月27日 | ||
| 発売価格 | MSRP:999ドル 創業者$ 1199 | MSRP:699ドル 創設者$ 799 | MSRP:499ドル 創業者599ドル | MSRP:599ドル 創設者$ 699 | ||
Nvidiaのチューリングアーキテクチャ:RT&テンソルコア
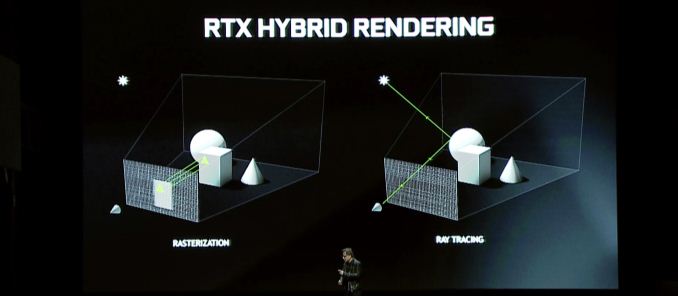
それで、チューリングはテーブルに何をもたらしますか? 全面的なマーキー機能はハイブリッドレンダリングです。これは、レイトレースと従来のラスター化を組み合わせて、両方のテクノロジーの強みを活用します. この発表は、本質的に今年初めからのNvidiaのRTX発表の継続です。そのため、その発表が少しまばらだと思ったら、ここに残りの話があります.
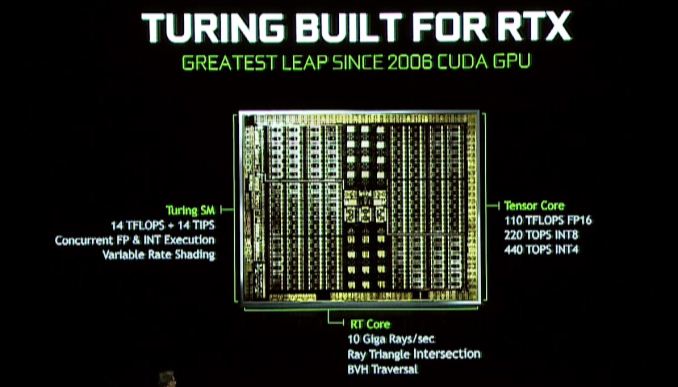
ここでの大きな変化は、Nvidiaがより速く、より効率的なハードウェアレイトレース加速を提供するために、さらに多くのレイトレースハードウェアをチューリングに含めることになることです。. チューリングアーキテクチャの新機能は、NvidiaがRTコアと呼んでいるものであり、現時点では十分な情報を得ていませんが、専用のレイトレースプロセッサとして機能しています。. これらのプロセッサブロックは、レイトリアング交差チェックと境界ボリューム階層(BVH)操作の両方を加速します。後者は、レイトレース用のオブジェクトを保存するための非常に人気のあるデータ構造です.
Nvidiaは、最速のGeForce RTX部品が1秒あたり100億(ギガ)の光線を鋳造できると述べています。.
チューリングアーキテクチャはまた、Voltaからテンソルコアを引き継いでおり、実際、これらはVoltaでさらに強化されています. テンソルコアは、複数のNVIDIAイニシアチブの重要な側面です. レイをトレースするレイをスピードアップすることに加えて、トリックのチューリングバッグにあるNvidiaの他のツールは、AIの除去を使用して画像をクリーンアップすることにより、シーンに必要な光線の量を減らすことです。. もちろん、それはテンソルコアの唯一の機能ではありません – NvidiaのAI/ニューラルネットワーキングエンパイア全体はほとんど構築されています – したがって、Gamescomの群衆の主要な焦点ではありませんが、これはNvidiaの最も強力なニューラルネットワーキングハードウェアが来ることを確認しますより広い範囲のGPUに.
一般的にハイブリッドレンダリングを見ると、これらの個々のスピードアップにもかかわらず、Nvidiaの全体的なパフォーマンスの約束がそれほど極端ではないことは興味深いです. 同社は、パスカルと比較して6倍のパフォーマンスブーストを約束していると言っていますが、これはどの部分に対しても指定していません. RTコアであっても、これが現実的な評価であるかどうかは時間がわかります。.
特にゲームの問題に関しては、ハイブリッドレンダリングの利点は潜在的に重要ですが、開発者がそれを使用する方法に大きく依存するでしょう. パフォーマンスの観点からは、ここで言うことがたくさんあるかどうかはわかりません。それは、レイトレースとハイブリッドレンダリングが最終的にレンダリング品質を向上させる機能であり、今日のアルゴリズムのパフォーマンスを向上させないためです. 確かに、今日のGPUでレイトレースをしようとした場合、それは非常に遅くなり、その結果、信じられないほどのスピードアップをチューリングしますが、このため、現在のハードウェアでスローパストレースシステムを使用する人はいません。. したがって、ハイブリッドレンダリングとは、現在のラスター化テクノロジーの近似とハッキングをより正確なレンダリング方法に置き換えることです。. 言い換えれば、「それを偽造」し、「作る」.」

これらの品質の利点は、通常、照明、影、反射の周りに密集しています. 3つの機能はすべて、本質的に光の特性に基づいており、単純な用語では光線として動き、これまでさまざまなアルゴリズムが関係する作業または「事前ベーキング」シーンを偽造しています. そして、現在のアルゴリズムは非常に良いですが、それでも正確には近いものではありません. そのため、改善の余地は明確です.


Nvidiaの一部は、特に世界的な照明の周りに投げ込まれています。これは難しいタスクの1つです. しかし、それらの照らされたオブジェクトの反射や影は言うまでもなく、他にも利益をもたらす他の照明方法もあります. そして正直なところ、これは言葉が貧弱なツールである場所です。レイトレースされた影がPCSSの偽の影、または事前に焼かれた照明のリアルタイム照明よりもどのように見えるかを説明することは困難です. それが、ビデオカード会社であるNvidiaが、これまで以上に難しい視覚的側面をプッシュする理由です.
全体として、ハイブリッドレンダリングはGeForce RTX 20シリーズのリンチピン機能です. GamescomとSiggraphのプレゼンテーションで行くと、Nvidiaがこのテクノロジーに関する今後数年間でGeforceブランドの成功を賭けていることは明らかです。. RTコアとテンソルコアは、半固定機能ハードウェアです。ラスター化に使用することはできず、それらに割り当てられたトランジスタは、そうでなければ、よりラスター化ハードウェアに専念している可能性のあるトランジスタです。. そのため、Nvidiaは、より大きなパスカルを構築するのではなく、ハイブリッドレンダリングルートに進むことにより、機会コストの面で非常に重要な動きをしました。.
その結果、Nvidiaは消費者レンダリングのパラダイムシフトを試みています。これは、2001年と2002年にPixel ShadersとVertexシェーダー(DX8&DX9 ERA Tech)の導入で以前にしか見たことがありません。. NVIDIAの他の開発者および消費者イニシアチブと同様に、MicrosoftのDirectX RayTracing(DXR)イニシアチブが非常に重要である理由です. Nvidiaは、ラスター化とレイトレースを混合するというこのビジョンについて、消費者と開発者を同じように販売する必要があります。. それ以上に、ムーアの法則が遅くなり続け、固定機能ハードウェアがより大きな効率を達成するための手段になるため、開発者はより専門的で固定された機能ユニットを操作するというアイデアに開発者を容易にする必要があります.
Nvidiaはハイブリッドレンダリングに農場を賭けていませんが、彼らはこの方法で市場を移動しようとしたことはありません. したがって、nvidiaがハイブリッドレンダリングとレイトレースにハイパーに焦点を合わせているように見える場合、それは彼らが. それは彼らの未来のビジョンであり、今では彼らは他のすべての人を乗船させる必要があります.
チューリングSM:専用のINTコア、統一キャッシュ、可変レートシェーディング
専用のRTおよびテンソルコアと並んで、チューリングアーキテクチャストリーミングマルチプロセッサ(SM)自体もいくつかの新しいトリックを学習しています. 特に、ここでは、Voltaのより斬新な変更の1つを継承しています。これにより、整数コアは、浮遊点Cuda Coresのファセットであるのではなく、独自のブロックに分離されました。. ここでの利点 – 少なくともVoltaで見たのと同じくらい – は、アドレスの生成をスピードアップし、融合したマルチアップ追加(FMA)パフォーマンスを高速化することです。私たちが今日見ているよりも使用されます.
チューリングSMには、nvidiaが「統一されたキャッシュアーキテクチャと呼んでいるものも含まれています.「私はまだNvidiaの公式SM図を待っているので、これが私たちがVoltaと見たのと同じ種類の統一であるかどうかは明らかではありません。ここで、L1キャッシュが共有メモリとマージされました – またはNvidiaがさらに一歩進んだか. とにかく、Nvidiaは「前世代」の帯域幅の2倍を提供していると言っています。.
最後に、シググラフチューリングのプレスリリースにも隠れていることは、可変レートシェーディングのサポートの言及です. これは、比較的若く、今後のグラフィックレンダリングテクニックであり、特にNvidiaがどのように実装しているかについて)についての情報が限られています). しかし、非常に高いレベルでは、次世代のNvidiaのマルチリスシェーディングテクノロジーのように聞こえます。これにより、開発者はさまざまな効果的な解像度で画面のさまざまな領域をレンダリングすることができます。それは最も有益です.
獣の給餌:GDDR6サポート
GPUが使用するメモリは外部企業によって開発されているため、ここには大きな秘密はありません. JEDECとそのビッグ3メンバーSamsung、SK Hynix、およびMicronはすべて、GDDR5とGDDR5Xの両方の後継者としてGDDR6メモリを開発しており、Nvidia HAはチューリングがそれをサポートすることを確認しました. メーカーに応じて、第一世代のGDDR6は一般に、メモリ帯域幅のピンあたり最大16Gbpsを提供するものとして宣伝されています。これは、Nvidiaの後期世代のGDDR5カードの2倍であり、Nvidiaの最新のGDDR5Xカードよりも40%速い速さ.
| GPUメモリ数学:GDDR6対. HBM2対. GDDR5X | ||||||||
| nvidia geforce rtx 2080 ti (GDDR6) | Nvidia GeForce RTX 2080 (GDDR6) | Nvidia Titan v (HBM2) | Nvidia Titan XP | nvidia geforce gtx 1080 ti | Nvidia GeForce GTX 1080 | |||
| 総容量 | 11 GB | 8 GB | 12 GB | 12 GB | 11 GB | 8 GB | ||
| ピンあたりのb/w | 14 gb/s | 1.7 gb/s | 11.4 gbps | 11 Gbps | ||||
| チップ容量 | 1 GB(8 GB) | 4 GB(32 GB) | 1 GB(8 GB) | |||||
| いいえ. チップ/kgsds | 11 | 8 | 3 | 12 | 11 | 8 | ||
| チップ/スタックあたりのb/w | 56 GB/s | 217.6 GB/s | 45.6 GB/s | 44 GB/s | ||||
| バスの幅 | 352ビット | 256ビット | 3092ビット | 384ビット | 352ビット | 256ビット | ||
| 合計b/w | 616 GB/s | 448GB/s | 652.8 gb/s | 547.7 gb/s | 484 GB/s | 352 GB/s | ||
| ドラム電圧 | 1.35 v | 1.2 V(?)) | 1.35 v | |||||
GDDR5Xと比較して、GDDR6は過去のメモリ世代ほど大きなステップアップではありません。GDDR6の革新の多くはすでにGDDR5Xに焼き付けられています. それにもかかわらず、非常にハイエンドのユースケースのHBM2とともに、GPU業界のバックボーンメモリになることが期待されています. ここでの原則の変更には、より低い動作電圧が含まれます(1.35V)、そして内部的にはメモリはチップごとに2つのメモリチャネルに分割されます. 標準の32ビット幅のチップの場合、これは16ビットのメモリチャネルのペアを意味します。. これは、非常に多数のチャネルがあることを意味しますが、GPUは、最初は非常に並列デバイスであるため、それを利用するように適切に位置付けられています。.

Nvidiaの一部は、最初のGeForce RTXカードが14GbpsでGDDR6を実行することを確認しました。. Nvidiaは、Quadro RTXカードにSamsungのGDDR6のみを使用していることを知っています – おそらく密度が必要なためです。ただし、GeForce RTXカードでは、すべてのメモリメーカーにフィールドが開かれている必要があります。. 長期的には、16GB密度チップを移動するか、現在使用している8GBチップでクラムシェルに移行する2つの手段が高容量カードに開かれています。.
オッズとエンド:nvlink sli、virtuallink、&8k hevc
これはNvidiaのGamescomプレゼンテーション自体では言及されていませんでしたが、NvidiaのGeforce 20シリーズのWebサイトは、SLIが再びハイエンドGeForce RTXカードで再び利用できることを確認しています。. 具体的には、RTX 2080 TiとRTX 2080の両方がSLIをサポートします. 一方、RTX 2070はSLIをサポートしません。これはそれを提供した1070からの逸脱です.
しかし、そのニュースのより大きな側面は、Nvidia独自のキャッシュコヒーレントGPUインターコネクトnvlinkが消費者カードに来ることです. GEFORCE GTXカードは、各カード間で2つのNVLINKチャンネルを実行してSLIをNVLINK上に実装します. 全二重帯域幅の合計50GB/秒 – つまり、各方向に50GBの帯域幅があります – これは、NVIDIAの以前のHB-SLIリンクに対する主要なアップグレードです. これは、NVLinkの他の機能の利点、特にキャッシュコヒーレンスの上にあります. そして、これはすべて重要な時期に来ます。.

今、大きな問題は、これがSLIの進行中の衰退を逆転させるかどうかであり、現時点ではやや悲観的なアプローチを取っていますが、Nvidiaからもっと聞きたいと思っています。. 50GB/秒はHB-SLIよりも大きな改善ですが、GPUが利用できるローカルメモリ帯域幅の448GB/秒(またはそれ以上)のほんの一部にすぎません。. したがって、AFRの同期または効果的なワークロード分割のいずれかで、マルチGPUレンダリングがドッグされた問題を解決しません. その点で、nvidiaがrtx 2070でnvlinkSLIをサポートしていないことを伝えている可能性があります.
一方、GamersはVRITUALLINKサポートを追加して、VRを楽しみにしていることを楽しみにしています. USB Type-C代替モードが先月発表され、15W+の電力、10gbpsのUSB 3をサポートします.1 Gen 2データ、および1つのケーブル全体にDisplayportHBR3ビデオの4つのレーン. 言い換えれば、それはDisplayPort 1です.4ビデオカードがVRヘッドセットを直接駆動できるようにすることを目的とした追加のデータとパワーとの接続. 標準はNvidia、AMD、Oculus、Valve、およびMicrosoftによって支えられているため、Geforce RTXカードは最終的に予想されるものの最初になります。.
| USB Type-C代替モード | ||||||
| virtuallink | displayport (4レーン) | displayport (2車線) | ベースUSB-C | |||
| ビデオ帯域幅(生) | 32.4Gbps | 32.4Gbps | 16.2Gbps | n/a | ||
| USB 3.Xデータ帯域幅 | 10gbps | n/a | 10gbps | 10gbps + 10gbps | ||
| 高速車線ペア | 6 | 4 | ||||
| マックスパワー | 必須:15W オプション:27W | オプション:最大100W | ||||
最後に、nvidiaは主題について一時的に触れただけですが、彼らのビデオエンコーダーブロックであるNVENCがチューリングのために更新されたことを知っています. NVENCの最新のイテレーションは、8K HEVCエンコーディングのサポートを特に追加します. 一方、nvidiaはエンコーダーの品質をさらに調整することもでき、ビデオビットレートが25%低いと以前と同様の品質を達成することができます.